新闻资讯
开云体育A 股/港股里“国产芯片、FP8 见识”短线大涨-开云官网kaiyun皇马赞助商 (中国)官方网站 登录入口
开端:贝叶斯之好意思开云体育
跟着深度学习模子(尤其是大限制生成模子)参数限制的扩展,对更高效的计较与存储有有计划的需求愈发激烈。诽谤数据类型位宽(精度)是一条行之有用的路子,但如安在诽谤位宽的同期保执准确度是一大挑战。
在预试验经由中,用更少的比特来涌现模子参数以及有关张量,已成为在不放浪准确度的前提下补助 GPU 着力的必备技艺。NVIDIA Blackwell 代 GPU 中引入的 Microscaling(MX)面目,将窄位宽浮点类型与更细粒度的按块缩放因子相集结,是这一标的的迫切进展;它让更多张量不错被量化,并让对这些张量的运算更高效。
deepseek一句话引爆国产算力芯片,国产芯片迎来解围质变要津点?从产业角度来看,将来的责任远不如看起来这样简短,前路仍是迟缓修远!
DeepSeek V3.1 公开点名用了 UE8M0 FP8 scale 并示意“下一代国产芯片”协同,媒体采集报谈后,A 股/港股里“国产芯片、FP8 见识”短线大涨,话题短暂出圈。同期,部分国产 GPU/NPU 声称“原生 FP8 / Block FP8”或器用栈可解救 FP8/MX,进一步强化了“软硬协同 → 开释带宽/功耗红利”的叙事。
UE8M0/FP8(MX)不是新见识,早在2023 年 OCP 就发布了
Microscaling(MX)v1.0(块大小 K=32、分享法式 UE8M0 等),把“块级缩放 + 窄位宽浮点”写成了行业范例。而到了2025 年,AI芯片之王NVIDIA
Blackwell 把 MXFP8/6/4 作念成张量核原生数据类型,硬件里径直处理“每 32 个数一个 2^k 法式”的逻辑(UE8M0),不再靠软件拼。官方尊府与开发者博客都强调了这点。有了原生解救后,MXFP8 试验端到端婉曲≈BF16 的 2×,而不是只在内核里“纸面提速”。(论文与官方文档均有明白。)

专诚把有关论文翻出来看了一下,内容未几,10多页,最新论文把能沉稳预试验的大模子的可复现作念法讲清了:通盘张量(含激活梯度)长入用 E4M3;法式用 UE8M0,且对 log2(amax/destmax) 取“进取整”,幸免因溢出导致的发散——这点明确永别于 OCP v1.0 的默许取整暴虐。并给出 8B/15T tokens 与 BF16 等精度的实证。
而其实最为要津的仍是在底层的软件与算子生态,Transformer Engine、cuDNN/cuBLAS 落地了 FP8/MX 的算子与数据流;NVIDIA NeMo、TE 用户手册给出了工程旅途。
大模子侧的果然案例越来越多:Nemotron-H、Llama 系列等公开材料都提到用 FP8 路子(早期多为按张量缩放,如今转向更细的块缩放/MX)。以致有 vLLM 在线 FP8 生成的旅途。这些都把“试验—推理—部署”的链条买通了。生态也在跨厂蔓延(举例 ROCm 侧的 Transformer Engine),进一步补助“通用感知”。
它具体解决了什么?
动态鸿沟不外载:整张量一次缩放常爱护不了“大值/小值”同期存在,容易溢出或压成 0;按块缩放能“就近对皆”,信息亏空更小。
带宽/显存压力小:元素 8 bit,每 32 个只加 1 字节法式元数据;比较“每块存 FP32 法式”,元数据流量省 75%。
硬件代价低:UE8M0 只编码 2^k,移位即可,要津旅途短、功耗低;对莫得圆善 FP8 乘加单元的芯片,落地门槛更低。
为什么会给国产芯片带来利好?在国产芯片宽阔仍以 FP16/BF16+INT8 通路为主的阶段,引入块级缩放 + 原生/近原生 FP8的存取与算子,不错在不放浪精度的前提下显耀降带宽、提婉曲,而UE8M0“幂次缩放”的硬件代价最低,因此是合适的过渡/长期有有计划,天然远够不上英伟达那样的着力,只可退而求其次,在某些端侧小场景尤其适用?
1)UE8M0 / FP8 / MXFP8 各自是什么?
UE8M0不是“另一种FP8”,而是MX(Microscaling)面目里的“块级缩放因子”——8 bit 全给指数(E8M0),只编码2的幂,用于给合并小块(典型 K=32)里的FP8元素长入定标;这样解码只需指数移位(shift),无谓作念浮点乘法,硬件要津旅途更短,带宽/能耗也更友好。
常见误区有哪些?
把 UE8M0 当成“第三种FP8”?不合。它是“缩放因子”的面目,元素依旧是 E4M3/E5M2。
觉得“有了UE8M0就势必大幅提速”,收益取决于硬件是否原生MX、模子是否带宽受限、以及通讯/内存是否成为新瓶颈。
把“75%从简”清醒为“总流量减少75%”,准确说是把“每块的缩放元数据”从 32b(FP32)降为 8b(UE8M0)→ 元数据部分着落 75%;对“举座块数据”的降幅更小,但仍有益好。
使用 UE8M0 FP8 scale,野心是与“微缩块面目(MX)”生态兼容;官方在外媒与社区页也提到与“新一代国产芯片”适配的取向。
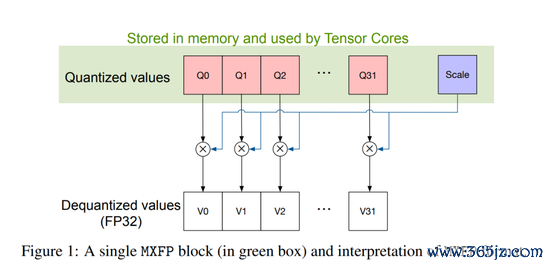
一个 MX 面目由:块大小 K、每块分享的缩放因子 X、块内元素的数据类型共同指定。K=32(适用于通盘 MX 类型)。X 的类型是 UE8M0(8 位指数、无余数、无象征),涌现 NaN 或 2 的幂(鸿沟 2^(−127) 到 2^127)。
给定源面目(畴昔 FP32)的 K 个数据 V_i,调节到 MX 面目时,需要计较 X 与 Q_i,使得 Q_i×X ≈ V_i。存储时写入 X 与 Q_i。Blackwell 的张量中枢会破钞 X 与两侧块的 Q_i 来作念点积;若累加输出为 FP32,则在后续算子需要 MX 面目时再将其回量化为 MX。
FP8(E4M3 / E5M2)
8位浮点的两种常用编码(1象征 + 指数 + 余数),业界已等闲用于试验/推理。E4M3精度更高、E5M2动态鸿沟更大。
MX(Microscaling)
把一个张量按固定小块(典型 K=32)切分;每块分享一个“缩放因子 X”(以幂次体式存放),块内元素用低位宽面目(如FP8)存储。这样既保留8比特的低带宽上风,又靠更细颗粒的定标获取更大的可用动态鸿沟与更稳的数值。MX 的块法式与元素面目互相落寞。
UE8M0
缩放因子的具躯壳式——无象征(U)、8位指数(E8)、0位余数(M0),即只消指数,莫得象征/余数;“ExMy”记法在 OCP 规格里明确:当 y=0(如E8M0)就不含象征位。它仅涌现 2 的整数幂,因此硬件解码是移位,不需浮点乘法。
MXFP8
指“元素为FP8”的MX面目鸠集;通盘MX具躯壳式的分享缩放,长入秉承 E8M0。常用的即是“UE8M0 + FP8(E4M3/E5M2),块大小K=32”。
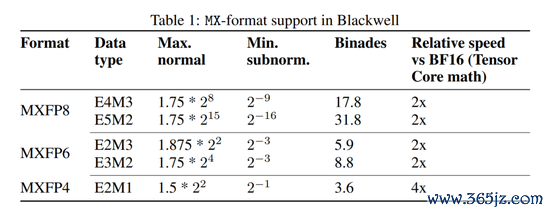
Blackwell 解救的 MX 面目
MXFP8:E4M3(最大概 1.75×2^8,最小约 2^(−9),可粉饰约 17.8 个 log2 桶),张量核相对 BF16 ~2× 婉曲。
MXFP8:E5M2(更大动态鸿沟,约 31.8 桶),张量核相对 BF16 ~2× 婉曲。
MXFP6:E2M3/E3M2(~2× 婉曲)。
MXFP4:E2M1(~4× 婉曲)。
注:E4M3 仅有一个 NaN 比特模式;E5M2 罢黜 IEEE-754 极度值语义。指数位越多→鸿沟越大;余数位越多→给定鸿沟内的精度越高。
论文娇傲在80 亿参数、15T 词元的预试验中,不雅察到 MXFP8 的考证困惑度与 BF16 匹配(全程互异 <0.5%)。卑劣任务(MMLU、9 项推理基准)分数也卓著。类似等价性在更小模子/数据上不异开发,从而使 MXFP8 成为更高效的预试验选项。
模子建设:32 层 Transformer,32 头,荫藏 4096,GQA 组 8,KV 通谈 128,预试验序列长 8192。学习率 6e-4 余弦衰减至 6e-6;数据搀和两阶段(先各种性、后高质料),60% 处切换。
试验平台:Megatron-LM;3072 张 Hopper GPU;批量 768。MX 运算通过将 BF16 输入在 GEMM 前调节为 MXFP8、GEMM 后再转回 BF16 来模拟。
评测:MMLU(5-shot)、9 项通用推理(1-shot)平平分。
MXFP8 守护 BF16/FP8 级准确度;在 Blackwell 上,MXFP8 张量核婉曲 ~2×BF16,端到端预试验更快;与传统 FP8 比较,MXFP8 配方更简短(通盘层均可量化,缩放由硬件处理),婉曲卓著或更佳。
2)它究竟解决了什么数值&硬件问题?
数值层面,传统“整张量缩放”在子8位(<8b)或顶点值散播下容易溢出/压成0;按块缩放能“就近”匹配每块的幅度散播,更好粉饰大/小值,减少饱和与下溢。实证标明在多项任务里,MX 径直替代 FP32 推理、以致用于低比特试验,也能接近/对皆 FP32/BF16 的精度。
E4M3 vs E5M2 的选型:在有了细颗粒块缩放的前提下,实践上畴昔长入用 E4M3(更高“采样精度”)能得到更稳的试验/卑劣表现;Blackwell 的 MX 试验配方也给出类似暴虐。
硬件/系统层面
UE8M0 = 2^k→ 解码只需移位;无谓作念浮点乘法、规格化或舍入,镌汰要津旅途、利于高频设想与能耗末端。
缩放元数据更轻:每块只多 8 bit 的 scale。相较“每块存一个 FP32 缩放”(32 bit),缩放元数据流量减少 75%;(举座块数据从 256b→264b 对比 256b→288b,总流量也更低)。
生态对皆:NVIDIA Blackwell 已将 MXFP8/6/4 作念成张量核原生数据类型(K=32、X=UE8M0),在其平台上 MXFP8 比较 BF16 的矩阵核婉曲标称 ~2×。这为上游模子与卑劣硬件的“共同谈话”定了规。
3)为什么说它“贴合下一代国产芯片”?
大宽阔已量产国产AI加快器仍以 FP16/BF16 + INT8 通路为主,对圆善 FP8 FMA 的硬件栈解救不一;而 UE8M0 的移位解码 + 块级FP8存算,实现难度和代价更低,更相宜阶段性演进旅途。
带宽/容量制约,更敏锐的环境里,FP8+块缩放能显耀诽谤 HBM/DDR 压力;这恰是国产芯片在功耗/能效/带宽方面最但愿“用算法/面目把水再挤出来”的标的。
国内媒体与机构报谈里,摩尔线程 MUSA 架构声称原生 FP8 张量加快,并点名能很好解救 UE8M0 FP8 Scale;芯原 VIP9000 NPU 亦被多家产业媒体与高管采访稿提到加多 FP8(E4M3/E5M2)解救,强调与主流框架/器用链的易部署性。
DeepSeek 明确秉承 UE8M0 FP8 scale,把软件侧配方与国产硬件的“最好责任点”对皆,试验上是在构建软硬协同的一致坐标系,诽谤生态碎屑化老本。
注:具体厂商/型号是否“原生 FP8 张量核”或“Block FP8”要以官方规格书/运行版块明白为准;媒体稿件与三方著述的口径可能滞后或存在表述互异。上文援用为公开报谈与产业采访。
4)它与“惯例 FP8”的联系(怎样搭配用)?
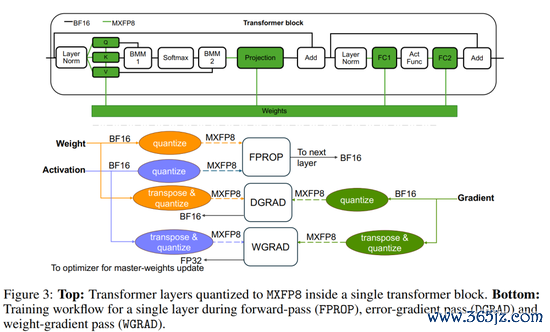
仍用 E4M3/E5M2(畴昔 E4M3 全程更稳),分享缩放用 UE8M0;典型块大小 K=32。这即是MXFP8。试验/推理常见作念法:权重/激活/梯度在 GEMM/CONV 里用 MXFP8,归一化/softmax/残差等用 BF16/FP32;累加一般在 FP32,主权重常保一份 FP32 “母本”。缩放算法按块取 amax 决定指数,进取取整以幸免溢出,再作念饱和式量化(首先上限则钳位)。这类配方在 Blackwell 的 MX 论文里给了具体方法与对比。
5)对模子精度与婉曲的“量化预期”
精度,在分类/语音/LLM 上,MX 径直投产/微调后能接近/对皆 FP32/BF16;对大模子的预试验,MXFP8 在合适配方下可与 BF16 等价的困惑度/卑劣得分。
婉曲/老本,在原生解救 MX 的硬件上,矩阵核婉曲~2×BF16,端到端试验/推理时刻和显存占用相应着落(果然收益取决于是否算子/带宽/通讯受限)。
对国内生态的实质真谛真谛有哪些?
UE8M0 FP8(MX)把模子数值配方和硬件实现老本一皆优化到了“兼容 & 高效”的平衡点:更稳的精度、更低的带宽、更短的要津旅途。DeepSeek 把试验/权重面目对皆到 MX 要领,等于在国产硬件侧“放下对接谈钉”。跟着更多芯片把 MXFP8 作念成“一等公民”,软硬协同的性价比才会果然体现出来。
是以,咱们不错看到,UE8M0 FP8(MX)是好“面目”,能显耀诽谤带宽/功耗、扩大可量化鸿沟;但“着力”取决于系统工程:是否有原生 MX 张量核、是否不休转置分量化和双副本支拨、是否站在 NVLink 级互联上扩展、以及器用链是否把配方一把梭。在这些方面,NVIDIA 当今端到端更圆善,是以你看到的“彰着差距”本色上是平台差距,而不是“UE8M0/MX 这条路子不行”。
是以,国产芯片再一次欢娱,可是咱们仍是需要闲适!
“有了 UE8M0 FP8(MX)面目是不是就等于坐窝得到英伟达那样的试验着力”?
谜底是不成!差距时时不在“面目本人”,而在算子/内核、内存与互联、框架与器用链、以及要领细节的一致性。从工程角度终止讲,不错看到哪些短板会径直吃掉咱们在论文或宣传里看到的收益。
1)数值与算法:要领一致性还没“完满对皆”
MX 的界说(K=32、每块分享 UE8M0 法式、块内元素用 FP8/FP6/FP4 等)是 OCP 要领的一部分;UE8M0 只编码 2 的幂(−127…127),本人很轻量。问题是:“怎样取整到 2 的幂”这件事,不同实现不完满一致。NVIDIA 的 MXFP8 试验配方里明确把法式取整改为进取取整(ceil(log2)),并给出消融:按 OCP v1.0 暴虐的“向下取整”在大限制预试验里会更易溢出/发散。若硬件/软件仍按 v1.0 来作念,试验沉稳性就可能对不上。
E4M3 “全量化”遴选:NVIDIA 的论断是权重/激活/激活梯度都用 E4M3(块缩放后需要的是精度而不是更大的指数鸿沟),这和许多“FP8=梯度用 E5M2”的老警戒不一样。配方差赓续,着力就会“看着像 MX,跑起来不像”。
2)算子与内核:没“原生 MX”就有隐性支拨
MX 需要在张量核里处理许多“每块一次”的法式。在软件里频繁处理这些缩放,相称贵;Blackwell 在硬件层把法式取整与量化塞进张量核教导旅途,才把这笔支拨吃掉。莫得这条硬件“捷径”,你在别家芯片上用 MX,内核层面的阑珊读改写/分量化会吞掉收益。
转置问题:Blackwell 的 MX 条目“沿归约维的块数据邻接”,试验时前后/反传会频繁换归约维;普通 FP8 转置是重排,MX 的转置要“分量化”,这在没作念专门硬件/内核优化时会相称痛。
双轴两份量化副本:为了同期就业行/列两条归约轴,试验框架畴昔需要给每个张量保两份 MX 量化版块;这既吃显存也加多数据搬运。NVIDIA 的论文和 TE 的工程 issue 都点名了这小数。
3)内存与互联:系统“地基”互异放大着力差距
NVLink / NVSwitch 的限制化上风:Blackwell 代把 NVLink 带宽拉到每 GPU 1.8 TB/s,并通过 NVLink Switch 把 72 GPU 拉进一个1.8 TB/s 保执的 NVLink 域,还能跨机柜扩展;这径直决定了FP8/MX 的带宽红利能否果然滚动成集群婉曲。若是替代平台只消 PCIe 或传统以太/IB,通讯相对吃紧,不异的 MX/FP8 算力上风会被All-Reduce/张量并行通讯对消。
4)生态与通用性:器用链还在“接入期”
框架 dtype 与编译器用解救未完满进修:PyTorch 中枢层靠近 MX 的基础类型(比如 E8M0、FP4)仍在激动中;Triton 也有“如安在谈话里露馅 MX/转置模式”的绽开问题。莫得一线框架的原生一等解救,通用性就会打折。
跨厂商 FP8 的“细节不一致”:比如 AMD 文档就明确写到 MI300 的 FP8 编码与 H100 不同;再访佛 MX 的法式取整互异,你在多家硬件之间移动“同名 FP8/MX”模子,可能需要重调节/重校准智力沉稳。
非英伟达平台的 MX 近况:
AMD:公开尊府已在教程/白皮书层面引入 OCP MX 见识与 FP8 解救,可是否有“原生 MX 块缩放硬件管线”尚非标配,多为软件旅途实验/过渡。
Intel Gaudi:官方强调 FP8 试验/推理算力与推理教程,但并未声称 MX 原生块缩放;若仅仅惯例 FP8(按张量/轴缩放),与 MX 的落地复杂度与收益弧线不同。
5)末端差距畴昔来自哪几件“最伤”的事?
数值细节不一致(法式取整、梯度面目):试验不稳或需要更保守的超参 → 有用婉曲着落。
莫得“内建 MX”的张量核:法式处理/转置分量化落在软件 → GEMM 旁路支拨变大。
存储/通讯瓶颈:双副本显存 + 边带法式 + 跨卡通讯不及 → MX 的带宽从简终了不了。
器用链与 op 粉饰不全:某些层(镶嵌/最终投影、BMM/softmax 等)仍高精度,若没对皆好实施盘算,端到端收益会被“非 MX 区段”稀释。
但关于夹缝中求存的国内芯片来说,这亦然算是一种未几的求变模式,将来任重而谈远。
哪怕莫得“原生 FP8 张量核”,也能通过“FP8 存取 + 快速移位解码 → 进 FP16/BF16 乘加”这条搀和旅途拿到带宽/显存层面的实效;硬件只需加轻量的法式表处理与移位单元。不异的内存带宽、不异的功耗预算下,模子不错更大、批量不错更足,单元 TCO 的婉曲更雅瞻念。DeepSeek 等模子侧明确用 UE8M0 的块缩放范式,软件栈(量化、校准、推理引擎)更容易在国产芯片上作念长入适配,减少“各玩各的”的碎屑化老本。比较“一步到位作念全功能 FP8 FMA 核”,先把 MX(按块缩放 + 移位解码)买通更现实,属于渐进式演进:
第一步:推理先行(权重 FP8 + 激活 BF16/FP16,累加 FP32);
第二步:部分试验链路 FP8 化(GEMM 骨干 FP8,归一化/Softmax 等保高精度);
第三步:硬件代际升级,再作念原生 MX/FP8 张量核。
“够不上英伟达着力,是以仅仅退而求其次、更稳妥端侧小场景?”
U1S1,现时如实存在差距:莫得“原生 MX”张量核、莫得高带宽互联(NVLink/NVSwitch 同级)、算子/框架解救不全时,UE8M0/FP8 的纸面上风会被内核支拨和通讯瓶颈吃掉。这是当下不少平台的现实。
但不等于“只可端侧”:
数据中心也能受益,前提是把块缩放和法式处理放进内核,减少“量化—反量化”的往复;许多国产有有计划在推理端已能落地这条搀和旅途。
端侧/边际天然更“对味”——内存窄、功耗紧的地点,UE8M0+FP8 的带宽/能耗收益会更径直、更沉稳;比如镶嵌式大谈话模子、语音/视觉边端模子、AI PC 的土产货推理。
政策不是“退而求其次”,而是“先吃敬佩性红利”:先把存取与带宽这半边红利吃干净,再逐渐把计较旅途FP8 化。
什么时候用它“最合算”?
推理优先:LLM、ASR、CV 大模子的权重 FP8(块缩放)+ 激活 16bit + FP32 累加;大幅降显存与权重带宽,延长/婉曲宽阔可见改善。
试验试点:中小限制预试验/赓续试验(SFT/蒸馏/LoRA),GEMM 骨干用 MXFP8,归一化/Softmax 等保高精度,先跑沉稳再扩限制。
带宽/功耗受限:AI PC/边际盒子/镶嵌式 SoC,压住功耗同期把模子体量拉上去。
是以,UE8M0 FP8(MX)= 低带宽 + 低实现门槛 + 饱胀稳的数值,对当下仍以 FP16/BF16+INT8 为主的国产芯片,是一条现实且渐进的增量路子。
不是只可端侧,但端侧/功耗敏锐场景的“性价比补助”最立竿见影;数据中心要思接近头部着力,需要算子级会通、块缩放下千里到内核、以及更好的互联带宽。先把权重/存取的红利吃到,再激动计较旅途与互联,这条路能走通,并且短期就有肉吃。
全文完。
 海量资讯、精确解读,尽在新浪财经APP
海量资讯、精确解读,尽在新浪财经APP
背负剪辑:杨赐 开云体育